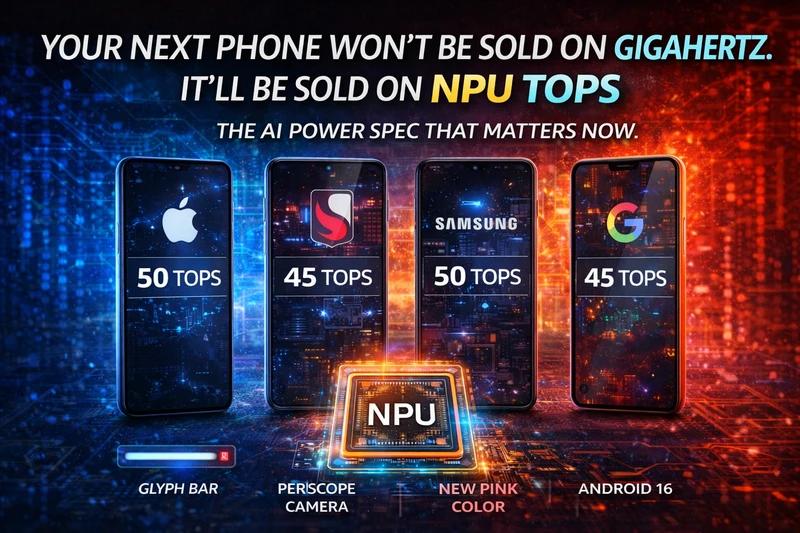
Your next phone won't be sold on gigahertz. Apple, Qualcomm, Samsung, and Google are racing to put double-digit NPU TOPS in every flagship—and suddenly the number that used to live in a footnote is the number that might decide whether your device runs the next wave of AI features or gets left behind.
TOPS—trillion operations per second—measures how much raw math a dedicated neural engine can do. It's the spec that actually predicts whether on-device AI will feel instant or laggy, and in 2026 it's finally stepping out of the shadow of CPU and GPU.
If you've compared phones in the last year, you've seen the numbers creep up: 45 TOPS, 50 TOPS, and now claims pushing higher. That's not marketing fluff. It's the industry betting that the next phase of "AI phone" isn't about having a chatbot in your pocket—it's about inference happening locally, at low latency, without burning your battery or sending every query to a server. The shift from "AI-ready" to "AI-native" hinges on having enough NPU TOPS headroom for the models and features coming in the next 24 months.
Why NPU TOPS suddenly matters
For years, chipmakers led with CPU cores and GPU performance. Neural engines existed, but they were secondary. That flipped when generative AI moved onto the device. Running a small language model or a real-time translation layer in a loop is exactly the kind of workload that burns power and bogs down general-purpose cores. A dedicated NPU does it in a fraction of the time and wattage.
Apple's M4 and A18 Pro, Qualcomm's Snapdragon 8 Gen 4, and Samsung's Exynos 2500 are all in the 40–50+ TOPS range for their NPUs. That's not a coincidence. It's the rough bar the industry has settled on for "good enough" for today's on-device models and the next year of features. Below that, you're more likely to see cloud fallbacks, longer waits, or locked-out features. AI inference at this scale is a different discipline from gaming or web browsing—and the vendors that invested early in neural engines are the ones now able to ship features that feel like magic instead of demos.
The TOPS trap: more isn't always better
Here's the contrarian bit: raw TOPS can mislead. A 50 TOPS NPU running inefficient software can feel worse than a 35 TOPS part that's well-optimized. Memory bandwidth, thermal headroom, and how well the stack (OS, frameworks, apps) actually uses the hardware matter as much as the number. Some vendors are better at turning TOPS into real-world responsiveness than others—and that gap will only get more visible as AI features multiply.
For real people, the shift is simple. When you pick up a 2026 flagship, the question isn't "how fast is the CPU?" It's "can it run the AI stuff I care about, all day, without begging the cloud?" That's an NPU question. Battery life for always-listening assistants, instant photo enhancement, and live transcription depends on dedicated neural silicon doing the heavy lifting. The devices that nail that balance will feel like a new category; the ones that don't will feel like last year's phone with a few extra toggles.
What comes next
2026 is the year neural processing stops being a bullet point and starts being the differentiator. We'll see more features that simply don't exist without a capable NPU—multimodal reasoning, faster personalization, and AI that actually stays on the device for privacy and speed. The brands that win won't be the ones with the biggest TOPS number on the box. They'll be the ones that make that number disappear into the experience.